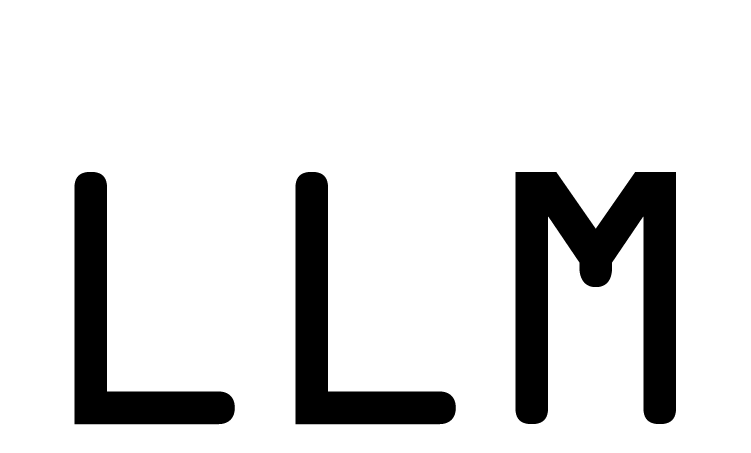





Artificial intelligence is transforming education, the job market, and social relationships
Large Language Models (LLMs) are groundbreaking artificial intelligence tools capable of processing and generating human-like text. They use advanced deep learning techniques to analyze context, understand linguistic nuances and produce consistent responses. Their applications include translation, data analysis, customer service automation and even code writing support.
In order to best approximate the essence of large language models, we must first clarify the relationship between three related yet distinct concepts: artificial intelligence (AI), natural language processing (NLP) and large language models (LLM).
AI is the broadest term, encompassing systems capable of mimicking human thinking and decision-making. Its purpose is to automate tasks that require intelligence, such as data analysis or pattern recognition. Examples of applications include autonomous cars or recommendation systems.
NLP, on the other hand, is a subfield of AI focused on human-machine interaction through language and includes:
NLP uses linguistic rules and statistics for tasks such as translation or text classification. Examples include simple chatbots.
LLM , on the other hand, is a specialized type of NLP models based on deep learning. Their features include:
To summarize - NLP focuses on structural language processing (e.g., syntax analysis), while LLM is "prediction machines" that simulate creativity through statistical patterns. AI, on the other hand, includes both NLP and other technologies such as computer vision.
| Aspect | AI | NLP | LLM |
|---|---|---|---|
| area | The whole field of technology | AI subset | A subset of NLP |
| Target | Task automation | Language processing | Text generation |
| Methodology | Machine learning, rules | Linguistics + statistics | Deep learning + big data |
| Resources | Moderate | Moderate | Enormous computing power |
| Restrictions | Depending on the specific technique | Rigid rules | Risk of errors and bias |
Moving from the general to the specific, we can already focus on the large language models (LLMs) themselves.
Large Language Model (LLM) is an artificial intelligence algorithm based on a transformer architecture, trained on huge text collections. Its name comes from the number of parameters (as many as hundreds of billions) to capture complex relationships between words and contexts.
Here we can distinguish three key features of LLM:
The easiest way to explain the importance of these features is to show how large language models work. The process of creating an LLM can be divided into three stages.
The first stage is training or perhaps a better expression - training LLM models, consisting of two phases.
Unsupervised phase, in which a given LLM model analyzes unlabeled data (books, articles, websites), learning basic linguistic relationships.
Tokenization is used for this purpose. In a nutshell, it involves transforming input text into smaller units called tokens. Tokens are words, character sets, or combinations of words and punctuation marks generated by large language models as they break down the text.
The second phase, on the other hand, is fine-tuning, in which self-supervised learning is used, where the model learns to predict missing pieces of text or classify sentences.
At the heart of LLM is the aforementioned transformer architecture. In its basic form, a transformer is a series of interconnected encoders and decoders. The input sequence is transformed into a vector representation, embedding the words in a specific layer. The weights of this layer are determined during training. Sound complicated? We are about to illuminate it in a table.
Earlier, the most important point here - the key element of transformers is the attention mechanism, which allows the model to focus on different parts of the input sequence while generating each element of the output sequence. This allows the model to better capture the context and relationships between words, even if they are far apart in the text.
It will be easiest to show this with simple examples for the three main layers that make up the transformer architecture:
| Layer | Function | Example of action |
|---|---|---|
| Integrative | Creates vectors representing the meaning of words | Encodes relationships like "rabbit → group → lagomorphs" |
| Comments | Determines the importance weights of individual words | In the sentence "Rabbit may belong to the group of lagomorphs or rodents" distinguish and correctly interpret the meaning and classification of the word "rabbit" |
| Predictions | Generates more tokens | Based on the sequence "Rabbit is a mammal belonging to the group..." predicts the token "lagomorphs" |
LLM models trained in this way, are ready to generate text, using probabilistic methods to produce consistent answers to the questions asked.
Of course, not only for generating text or providing answers, but also for context-supported automatic translations between languages (e.g., distinguishing homonyms), summarizing documents by extracting the most important information from them and presenting it in a concise form, writing and correcting programming code (code autocomplete and debugging) or automating customer service (virtual assistants).
LLMs can also be used to analyze sentiment in reviews, comments or social media posts. They can also classify texts by subject matter or other more specific criteria.
It is worth mentioning here in an educational context that majors such as computer science at PJAIT cover broad issues related to LLM, while the Artificial Intelligence in Business postgraduate program teaches the practical use of these models in management.
In recent years, a number of large language models have been developed, which have gained wide popularity and found a variety of applications. By way of example, these include:
Despite their impressive capabilities, large language models have their limitations, and their developers face a number of challenges. These can be mentioned first and foremost:
Large language models (LLMs) are advanced artificial intelligence algorithms that, by training on huge text datasets and using transformer architecture, have gained the ability to generate and process natural language on an unprecedented scale.
LLMs represent a breakthrough in the field of natural language processing (NLP) and are used in a variety of areas - from content creation to translation to business process automation. Despite some limitations, such as hallucinations and lack of timeliness, large language models are constantly evolving, opening up new possibilities for learning, business and everyday use.
The development of large language models is certainly opening up new opportunities for business, education and science. For those interested in developing their competencies in this area, undergraduate and postgraduate degrees in Computer Science, as well as postgraduate programs such as Artificial Intelligence in Business, provide an excellent opportunity to acquire knowledge and skills useful in this rapidly developing field.
Contact the Recruitment Department to get answers to all your questions.
rekrutacja@pja.edu.pl